Yolo
Yolo V1
简介
在Yolo v1提出之前,R-CNN算法在目标领域独占鳌头,但由于R-CNN的网络结构是双阶段(two stage)的特点,使得它的检测速度不能满足实时性。2016年,Joseph Redmon、Santosh Divvala、Ross Girshick等人提出了一种单阶段(one-stage)的目标检测网络。它的检测速度非常快,每秒可以处理45帧图片,能够轻松地实时运行。由于其速度之快和其使用的特殊方法,作者将其取名为:You Only Look Once
YOLO 的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框) 的位置及其所属的类别。

实现细节
检测策略
- 将一幅图像分成 S×S个网格(grid cell),若某个 object 的中心落在这个网格中,则这个网格就负责预测这个object。
- 每个网格要预测 B 个bounding box,每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值。
- 每个网格还要预测一个类别信息,记为 C 个类。
- 总的来说,S×S 个网格,每个网格预测 B个bounding box ,预测 C 个类。网络输出就是一个 S × S × (5×B+C) 的张量。
目标损失函数

- 损失由三部分组成,分别是:坐标预测损失,置信度损失,类别预测损失
Yolo V2
简介
更快更准
- 重点解决Yolo v1 召回率和定位精度方面的不足
- 可以接受不同尺寸的图片输入
- 引进Anchor机制
网络结构
Yolo v2采用Darknet-19作为特征提取网络

- 使用多个3*3卷积核
- 在每一层的卷积之后,都增加了Batch Normalization进行预处理
- 采用了降维的思想,把1x1的卷积置于3x3之间,用来压缩特征
改进方法
Batch Normalization
Batch Normalization简称BN,即批量标准化,对数据进行预处理,能够提高训练速度,提升训练效果。

引入Anchor Box机制
引入Anchor Box锚框机制,加快前期网络训练收敛速度

Convolution With Anchor Boxes
Yolo v1中,一张图片被分割成7x7网络,当一个网格中同时出现多个类时,就无法检测出所有类,Yolo v2做出了相应的改进:
- 提高最后的卷积层的输出的分辨率特征
- 缩减网络为416x416,使得网络输出的特征图由奇数大小的宽和高,进而使得在划分单元格的时候,只有一个中心单元格,得到的输出是13x13的像素特征
聚类方法选择Anchors
Fine-Grained Features
细粒度特征, 可理解为不同层之间的特征融合,从而来提高对小目标的检测能力。
Yolo V3
简介
2018年,作者 Redmon 又在 YOLOv2 的基础上做了一些改进。特征提取部分采用darknet-53网络结构代替原来的darknet-19,利用特征金字塔网络结构实现了多尺度检测,分类方法使用逻辑回归代替了softmax,在兼顾实时性的同时保证了目标检测的准确性。
网络结构

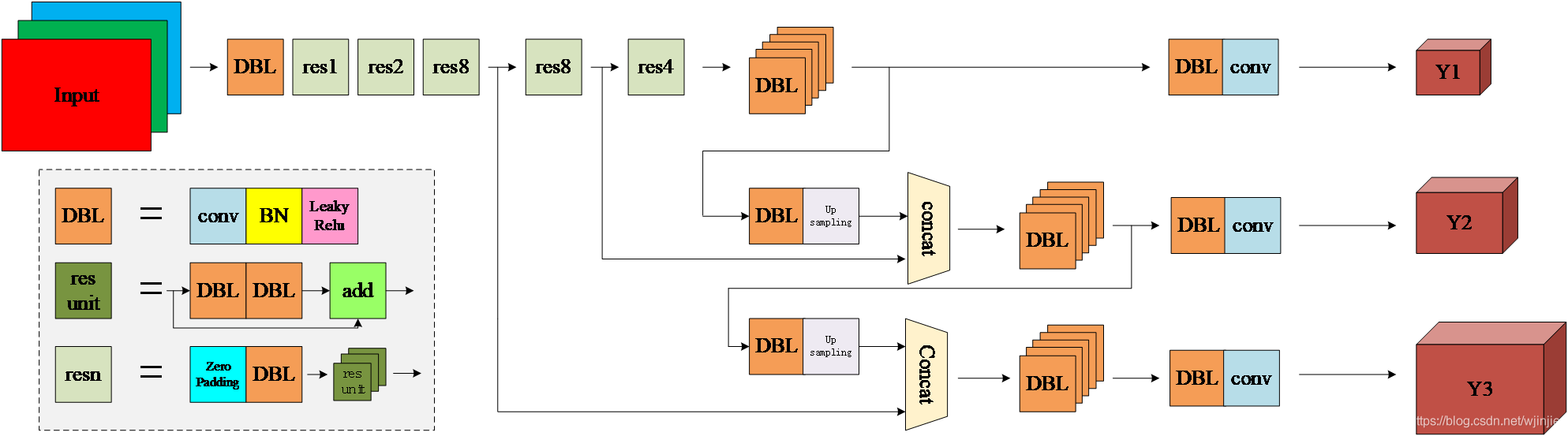
- DBL: 一个卷积层、一个批量归一化层和一个Leaky ReLU组成的基本卷积单元。
- res unit: 输入通过两个DBL后,再与原输入进行add;这是一种常规的残差单元。残差单元的目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
- resn: 其中的n表示n个res unit;所以 resn = Zero Padding + DBL + n × res unit 。
- concat: 将darknet-53的中间层和后面的某一层的上采样进行张量拼接,达到多尺度特征融合的目的。这与残差层的add操作是不一样的,拼接会扩充张量的维度,而add直接相加不会导致张量维度的改变。
- Y1、Y2、Y3: 分别表示YOLOv3三种尺度的输出。
改进方法
多尺度预测
YOLOv3 选择了三种不同shape的Anchors,同时每种Anchors具有三种不同的尺度,一共9种不同大小的Anchors

损失函数
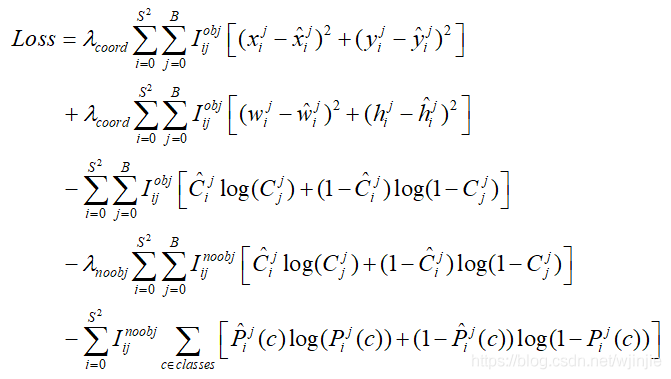
多标签分类
YOLOv3在类别预测方面将YOLOv2的单标签分类改进为多标签分类,在网络结构中将YOLOv2中用于分类的softmax层修改为逻辑分类器
Yolo V4
简介
Yolo系列的作者Redmon处于道德方面的考虑,声明不再进行相关的工作,但Alexey Bochkovskiy等人与Redmon取得联系,正式将他们的研究命名为YOLOv4。
Yolo V4是一个高效而强大的目标检测网络,更加适合在单GPU上训练
网络结构

Yolo V4的网络结构是由CSPDarknet53,SPP, PANet,Yolo V3头部等组成
CSPDarknet53
CSPNet全称是Cross Stage Partial Network, CSPNet的主要目的是能够实现更丰富的梯度组合,同时减少计算量。这个目标是通过将基本层的特征图分成两部分,然后通过一个跨阶段的层次结构合并它们来实现的。
将原来的Darknet53与CSPNet进行结合
使用Mlsh激活函数代替了原来的Leaky RELU
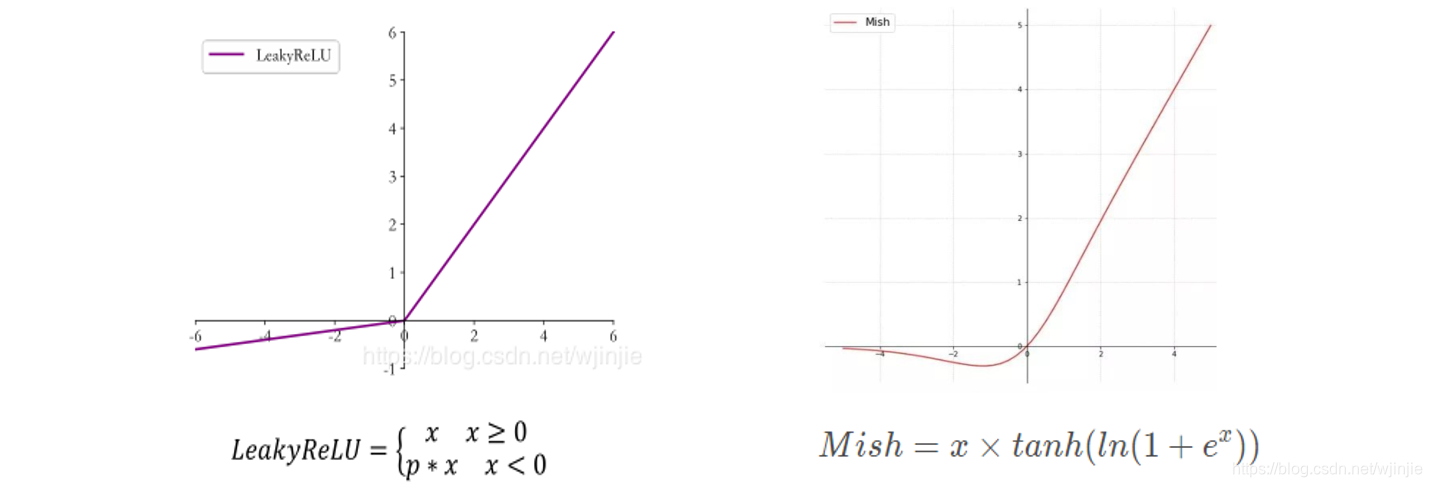
SPP
SPP最初的设计目的是用来使卷积神经网络不受固定输入尺寸的限制。在YOLOv4中,作者引入SPP,是因为它显著地增加了感受野,分离出了最重要的上下文特征,并且几乎不会降低的YOLOv4运行速度。
PANet

- FPN主要通过融合高底层特征提升目标检测的效果,尤其是可以提高小尺寸目标的检测效果。
- Bottom-up Path Augmentation的引入主要是考虑网络浅层特征信息对于实例分割非常重要,因为浅层特征一般是边缘形状等特征。
- Adaptive Feature Pooling用来特征融合。也就是用每个ROI提取不同层的特征来做融合,这对于提升模型效果显然是有利无害。
- Fully-connected Fusion是针对原有的分割支路(FCN)引入一个前背景二分类的全连接支路,通过融合这两条支路的输出得到更加精确的分割结果。
Tricks
Bag of freebies
以数据增强方法为例,虽然增加了训练时间,但不增加推理时间,并且能让模型泛化性能和鲁棒性更好。
改进方法
Mosaic
作者提出的一种数据增强方法,使用四张图片进行拼接
SAT
SAT是一种自对抗训练数据增强方法,这一种新的对抗性训练方式。在第一阶段,神经网络改变原始图像而不改变网络权值。以这种方式,神经网络对自身进行对抗性攻击,改变原始图像,以制造图像上没有所需对象的欺骗。在第二阶段,用正常的方法训练神经网络去检测目标。
CmBN
CmBN的全称是Cross mini-Batch Normalization,定义为跨小批量标准化(CmBN)。CmBN 是 CBN 的改进版本,它用来收集一个batch内多个mini-batch内的统计数据。
该文章为记录自己的学习,不做任何商业用途
参考文章:YOLO系列算法精讲:从yolov1至yolov4的进阶之路(2万字超全整理,建议收藏!)不积跬步,无以至千里!-CSDN博客yolo系列算法
如有侵权,请立刻联系,我将即刻删除相关内容