机器学习算法竞赛实战(一)
本文为学习《机器学习算法竞赛实战》时所做的笔记,仅供复习总结参考,不做任何商业用途,如有侵权,请联系删除。
初见竞赛
竞赛平台
- Kaggle
- 天池
- DataFountain
- DataCastle
- Kesci
- JDATA
竞赛流程
吴恩达老师曾经说过,机器学习算法在大多数时候就只是数学统计而已,数据相关的特征工程直接决定了模型的上限,而算法只是不断逼近这个上限而已。
- 问题建模
- 数据探索EDA(Exploratory Data Analysis)
- 特征工程
- 模型训练
- 模型融合
问题建模
当竞赛者拿到题目的时候,首先考虑的事情就是问题建模,同时完成基线(baseline)模型的管道(pipeline)搭建,从而能够第一时间获得结果上的反馈,帮助后续工作的进行。
赛题理解
业务背景
- 深入业务
- 明确目标
数据理解
数据基础层
数据基础层重点关注的是每个数据字段的来源,生产过程,取数逻辑,计算逻辑等。
数据描述层
数据描述层主要是在处理好的数据基础层上进行统计分析和概括描述,这个层面的重点在于尽可能地通过一些简单统计量来概括整体状况,也使得参赛者能够清晰地知晓数据的基本情况。
评价指标
分类指标
分类问题不仅是竞赛中常出现的一种核心问题,也是实际应用中常见的一种机器学习问题。
错误率与精度
准确率与召回率
真实类别
1
0
预测类别
1
True Positive(TP)
False Positive(FP)
0
False Negative(FN)
Ture Negative(TN)
- 准确率P \(\frac{TP}{TP+FP}\)
- 召回率R \(\frac{TP}{TP+FN}\)
F1-score
\[ F1=2\*\frac{P\*R}{P+R} \]
ROC曲线

\[ FPR = \frac{FP}{FP+TN}\ 负样本中的错判率(假报警率)\\\\ TPR = \frac{TP}{TP+FN}\ 判对样本中的正样本率(命中率)\\\\ ACC = \frac{TP+TN}{P+N}\ 判对准确率 \]
在ROC曲线图中,横坐标为FPR,纵坐标为TPR
AUC
AUC表示ROC曲线下的面积,主要用于衡量模型的泛化性能,即分类效果的好坏。AUC是衡量二分类模型优劣的一种评价指标,表示正例排在负例前面的概率。

对数损失 \[ \log{loss}=-\log{P(Y|X)}\\ \log{loss}=-\frac{1}{N}\sum_{i=1}{(y_i\log{p_i}+(11-y_i)\log{(1-p_i)}} \] 对数损失主要是评价模型预测的概率是否准确,它更加关注和观察数据的吻合程度,而AUC评价的则是模型把正样本排到前面的能力。
回归指标
平均绝对误差 \[ MAE(y,y_i')=\frac{1}{m}|y_i-y_i'| \] 在XGBoost里面,可以使用平均绝对误差作为损失函数进行模型训练,但是经常会使用Huber损失进行替换,因为平均绝对误差自0处不可导。
均方误差 \[ MSE(y, y')=\frac{1}{m}\sum_{i=1}^{n}{(y_i-y_i')} \] 使用均方误差的模型会赋予异常点更大的权重
均方根误差 \[ RMSE(y, y')=\sqrt{\frac{1}{m}\sum_{i=1}^{n}{(y_i-y_i')^2}} \]
平均绝对百分比误差 \[ MAPR(y, y')=\frac{1}{m}\sum_{i=1}^n{\frac{|y_i-y_i'|}{y_i'}} \] 它是比均方根误差更加健壮的评价指标,相当于把每一个点得到误差进行了归一化,降低了个别离群点对绝对误差带来的影响。
样本选择
- 数据集过大
- 数据噪声
- 数据冗余
- 正负样本分布不均衡
准确方法
- 简单随机抽样
- 分层采样
- 评分加权处理
- 欠采样
- 过采样
线下评估策略
强时序性问题
对于含有明显时间序列因素的赛题,可以将其看作是强时序性问题,即线上数据的时间都在离散数据集之后,这种情况下就可以采用时间上最接近测试集的数据做验证集,且验证集的时间分布在训练集之后。
弱时序性问题
这类问题的验证方式主要为K折交叉验证(K-fold Cross Validation),我们一般取K=5或10
1
2
3
4
5
6from sklearn.model_selection import KFold
NFOLDS = 5
folds = KFlod(n_splits = NFOLDS, shuffle=TRUE, random_state = 2021)
for trn_idx, val_idx in folds.split(X_train, y_train):
train_df, train_label = X_train.iloc[trn_idx, :], y_train[trn_idx]
valid_df, valid_label = X_train.iloc[val_idx, :], y_train[val_idx]实战案例
House Prices - Advanced Regression Techniques | Kaggle
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import OneHotEncoder
import lightgbm as lgb
train = pd.read_csv('../input/house-prices-advanced-regression-techniques/train.csv')
test = pd.read_csv('../input/house-prices-advanced-regression-techniques/test.csv')
train.describe()
# 对数据进行基本处理
all_data = pd.concat((train, test))
# one-hot编码
all_data = pd.get_dummies(all_data)
# 填充缺失值
all_data = all_data.fillna(all_data.mean())
# 数据切分
X_train = all_data[:train.shape[0]]
X_test = all_data[train.shape[0]:]
y = train.SalePrice
# K折交叉验证
from sklearn.model_selection import KFold
folds = KFold(n_splits=5, shuffle=True, random_state=2021)
# 模型参数
params = {'num_leaves': 63, 'min_child_samples': 50, 'objective': 'regression', 'learning_rate': 0.01,
'boosting_type': 'gbdt', 'metric': 'rmse'}
for trn_idx, val_idx in folds.split(X_train, y):
trn_df, trn_label = X_train.iloc[trn_idx, :], y[trn_idx]
val_df, val_label = X_train.iloc[val_idx, :], y[val_idx]
dtrn = lgb.Dataset(trn_df, label=trn_label)
dval = lgb.Dataset(val_df, label=val_label)
bst = lgb.train(params, dtrn, num_boost_round=1000, valid_sets=[dtrn, dval],
early_stopping_rounds=100, verbose_eval=100)数据探索
数据初探
分析方法
- 单变量可视化分析
- 多变量可视化分析
- 降维分析
明确目的
- 数据集的基本情况
- 重复值,缺失值和异常值
- 特征之间是否冗余
- 是否存在时间信息
- 标签分布
- 训练集与测试集的分布
- 单变量/多变量分布
1
2
3
4
5stats = []
for col in train.columns:
stats.append((col, train[col].nunique(), train[col].isnull().sum() * 100 / train.shape[0], train[col].value_counts(normalize=True, dropna=False).values[0] * 100, train[col].dtype))
stats_df = pd.DataFrame(stats, columns=['Feature', 'Unique_values', 'Percentage of missing values', 'Percentage of values in the biggest category', 'type'])
stats_df.sort_values('Percentage of missing values', ascending=False)[:10]
变量缺失值可视化
1
2
3
4missing = train.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()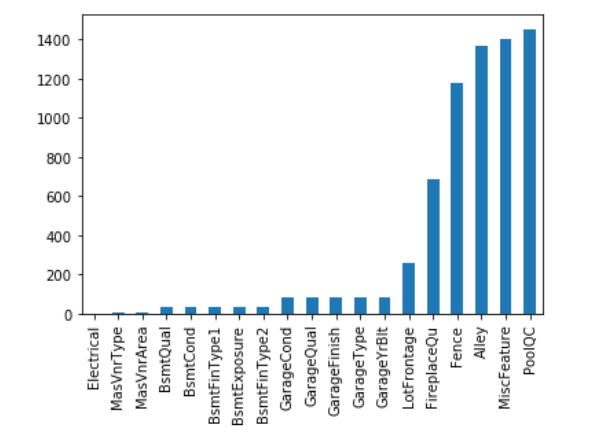
变量分析
单变量分析
标签
1
train['SalePrice'].describe()1
2
3import scipy.stats as st
plt.figure(figsize=(9, 8))
sns.distplot(np.log(train['SalePrice']), color='b', bins=100, hist_kws={'alpha': 0.4})
连续型
相似性矩阵
1
2
3corrmat = train.corr()
f, ax = plt.subplots(figsize=(20, 9))
sns.heatmap(corrmat, vmax=0.8, square=True)
多变量分析
1
2
3
4
5
6# 房屋位置和评价的关系
plt.style.use('seaborn-white')
type_cluster = train.groupby(['Neighborhood','OverallQual']).size()
type_cluster.unstack().plot(kind='bar',stacked=True, colormap= 'PuBu', figsize=(13,11), grid=False)
plt.xlabel('OverallQual', fontsize=16)
plt.show()
模型分析
学习曲线
- 欠拟合学习曲线
- 过拟合学习曲线
特征重要性分析
1
2
3
4
5
6
7
8from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, LassoCV, LassoLarsCV
from sklearn.model_selection import cross_val_score
def rmse_cv(model):
rmse= np.sqrt(-cross_val_score(model, X_train, y, scoring="neg_mean_squared_error", cv = 5))
return(rmse)
model_ridge = Ridge()1
2
3
4
5
6
7
8alphas = [0.05, 0.1, 0.3, 1, 3, 5, 10, 15, 30, 50, 75]
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean()
for alpha in alphas]
cv_ridge = pd.Series(cv_ridge, index = alphas)
cv_ridge.plot(title = "Validation")
plt.xlabel("alpha")
plt.ylabel("rmse")
1
2
3
4
5
6
7
8
9
10
11
12model_lasso = LassoCV(alphas = [1, 0.1, 0.001, 0.0005]).fit(X_train, y)
coef = pd.Series(model_lasso.coef_, index = X_train.columns)
import matplotlib
import matplotlib.pyplot as plt
imp_coef = pd.concat([coef.sort_values().head(10),
coef.sort_values().tail(10)])
matplotlib.rcParams['figure.figsize'] = (8.0, 10.0)
imp_coef.plot(kind = "barh")
plt.title("Coefficients in the Lasso Model")
机器学习算法竞赛实战(一)https://www.spacezxy.top/2021/10/10/ML-Pratice/ML-Algorithm-pratice-1/